


Table of contents
입사할 때 진행중이던 sprint2부터 시작해서 kanban과 병행하며 일을 하다가 최근에 sprint4를 끝마쳤다. 서핏팀에서는 팀에 맞는 설계 방법을 만들기 위해서 매 프로젝트마다 다른 방식으로 설계 작업을 진행한다. sprint2와 3에서는 유저 스토리만을 이용해서 설계를 했고, sprint4에서는 UML을 이용해서 유즈케이스 다이어그램과 액션 다이어그램을 그리면서 플로우를 그리고, 스프레드 시트로 데이터를 정의해서 설계했다.
글을 쓰는 지금 이 시점에서 sprint5를 진행하고 있는데, 그간 경험한 설계 방식들을 기록하면 두고두고 볼 것 같아 정리하려고 한다.
업무(기능) 정의하기
만들 프로덕트에 대해 대략적인 기능들이 나오면 그 기능을 사용할 수 있는 경우를 정리한다. 그동안 프론트엔드 관점에서 요구사항을 정의하고 작업을 만들었는데, 이렇게 이 작업을 하면서 시야가 굉장히 넓어지는 느낌을 받았다.
(프론트엔드를 만드는게 아닌 프로덕트를 만든다는 생각이 들었음)
이 설계 방법의 장점은
프로덕트 플로우를 조금 더 꼼꼼하게 망라한다.
프론트엔드, 백엔드뿐만 아니라 프로덕트의 여러 이해 관계자들로 하여금 무슨 일을 해야할 지 상기시킬 수 있다.
해당 자료를 이용해서 다른 설계 작업이 가능하게 된다.
정도가 있을 것 같다.

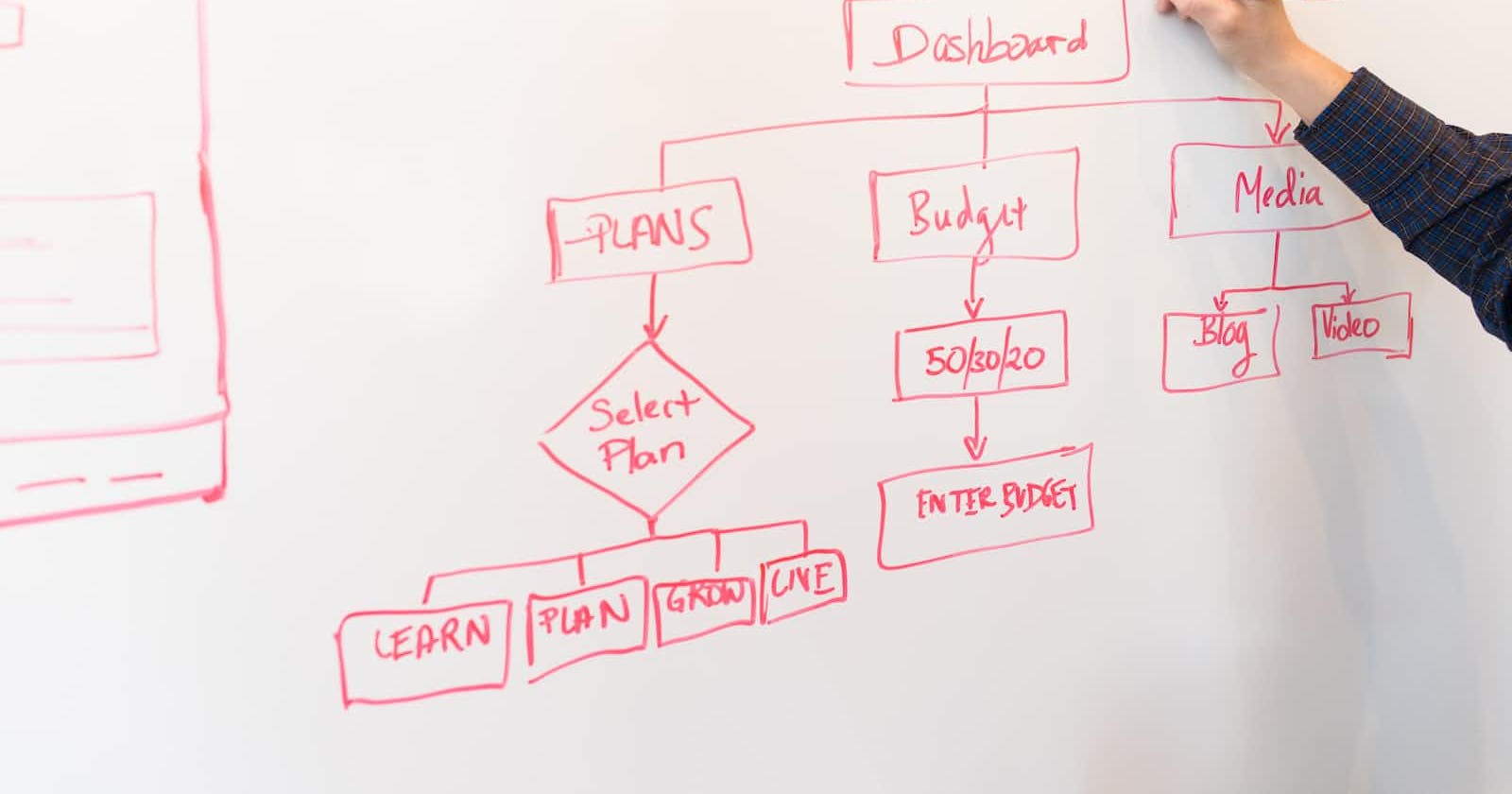
UML로 다이어그램 그리기
전 단계에서 정리한 자료를 바탕으로 기능들이 서로 어떤 관계가 있는지 유즈케이스 다이어그램으로 표현할 수 있다.

이 자료를 만들면 기능 각각의 상관관계를 한눈에 알기 좋다. 이를 통해 자연스러운 개발 흐름을 만들 수 있고 자연스레 시간을 아낄 수 있다는 효과를 얻어낸다.
개발 작업을 하다보면 개발하고 있는 부분의 컨텍스트에 매몰되기 일쑤다. 그렇기 때문에 이런 설계 작업은 귀찮더라도 넓은 시야를 가지기 위해 꼭 해야한다!
그 다음으로 액션 다이어그램을 이용해서 각 기능들의 상세 플로우를 설계한다. 액션 다이어그램은
~~ 버튼 클릭
~~ 입력
~일 때 얼럿 표시
처럼 어떤 유저스토리(기능)를 액션 기반으로 나눠서 UML로 구성된다.
이 자료를 만들면서 공통적으로 재사용할 수 있는 부분과 그렇지 않은 부분들을 분리해서 정리했다. 그 덕분인지 자연스러운 개발 순서를 정하고 어떤 기준으로 작업을 배분할지 계획을 세울 수 있었다.

사용되는 데이터 정의
페이지 단위로 사용되는 데이터를 모두 정의한다. 이 작업에서는 화면단에 표출되는 데이터와, 백엔드에서 다뤄지는 데이터를 따로 정의한다. 따로 정의하면 자연스럽게 빠진 데이터들을 체크할 수 있기 때문이다.
나는 프론트엔드 개발자로서 화면단에 표출되는 데이터들을 정의했다. 시안에 표시되는 데이터를 확인하면서 다시 한 번 플로우도 체크할 수 있게 되었다.

이렇게 사용될 데이터를 정의해두면 API 작업할 때 이 자료를 참고해서 작업할 수 있게 된다. 또한, 프론트엔드에서는 API가 나오기 전에 데이터를 mocking해서 작업을 빨리 할 수 있다는 장점이 있다. 트래킹 로그를 미리 설계할 수 있다는 점도 좋다.
정리
서핏에서는 이러한 설계 과정을 거쳐서 프로덕트를 만든다. 이런 설계 과정을 통해서 프로덕트를 만들면, 그 프로덕트가 완전히 내것이 된다는 점이 참 좋은 것 같다. 앞으로 최대한 다양한 설계 과정을 경험해서, 서핏에 꼭 맞는 설계 방법을 만들 게획이다.